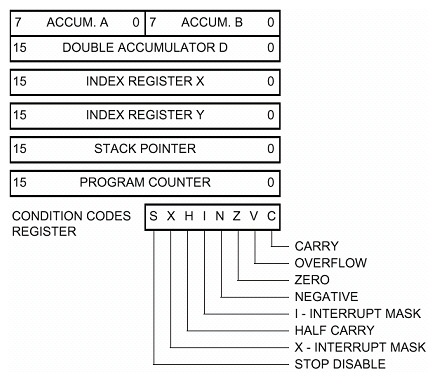
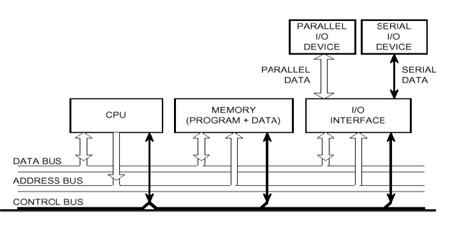
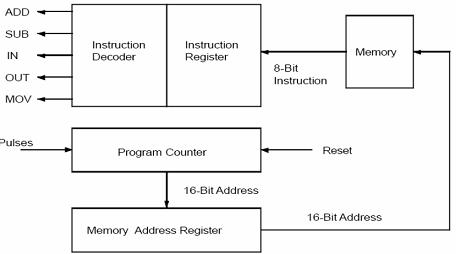
Assembly programming is low-level programming using some basic syntax to represent machine code for a specific CPU. An assembler is used to translate the assembly code into the machine code for the target computer.
A program created from assemblhy can be more efficient and faster than a program created with a compiler. One example of why this occurs is because a compiler will store intermediate values used in a calculation in memory whereas a program written in assembly can store the intermediate values in a register which is much faster. However, while there may be performance benefits to programming so close to the machine level, there is a great deal of added complexity which a high-level programming language can remove.
Table 5.1 Source Code Fields [1]
| Label Field | Opcode Field | Operand(s) Field | Comment Field |
| Example: | ldaa | #$64 | ; Initialize A with hexadecimal 64 |
- A label must start with an alphabetic character
- The label must start in the first column of the source code line unless it ends with a colon.
- Uppercase and lowercase characters are distinct by default but case sensitivity may be turned off.
- A label may end with a colon (:)
- A label may appear on a line by itself
- The label is optional but when used it can provide a symbolic memory reference such as a branch instruction address, or a symbol for a constant.
- The opcode field contains either a mnemonic for the operation, an assembler directive or pseudo-operation, or a macro name. For the opcode field, the assembler will convert all uppercase letters to lowercase so this field is not case sensitive.
- The interpretation of the operand field depends on the opcode.
- The operand must follow the opcode.
- Operands can be the symbols, constants, or expressions that are evaluated by the assembler.
- The operand field also specifies the addressing mode for the instruction.
Using Macros
A macro can be used to give a symbolic name to a group of instructions that are used often. In the source code the macro should be given a name using the label field and then two commands (MACRO & ENDM) are used to indicate the start and finish of the macro. The assembler will then replace every occurrence of the macro with the set of instructions.
| Add_B_and_C: | MACRO |
| MOV A,C ADD A,B MOV C,A ENDM |
Macro vs Sub-Routine
A macro and a sub-routine are similar except for the following differences:
- With a sub-routine the code is present only once. With a macro, the code is inserted in the place of the macro whenever it is used. Therefore, if macros are used instead of sub-routines, the code will end up being longer.
- With a sub-routine a jump must occur in order to find and execute the sub-routine code. With a macro, this is not required because the code has already been inserted directly. Therefore, a sub-routine will be slightly slower than a macro.
Using either a sub-routine or a macro makes changing the code much easier because changes can be done in one place rather than in each specific location where the code would be used. They also make the code easier to understand.
Assembler Instructions
ORG – Set the program counter to the origin of the program
EQU – Associate the value of an expression with a symbol
SET – Can be used instead of equal. With set, the value can be redefined
DC – Define a constant value
DCB – Define a constant block
DS – Define storage
Example 5-9 ORG – Set Program Counter to Origin for Absolute Assembly [1]
| 0000 c000 | ROM: | EQU | $c000 | ; Location of ROM |
| 0000 0800 | RAM: | EQU | $0800 | ; Location of RAM |
| 0000 0A00 | STACK: | EQU | $0a00 | ; Location of stack |
| ; | ||||
| ORG | ROM | ; Set program counter to ROM | ||
| ; | ||||
| 00c000 CF0a 00 | lds | #STACK | ; Initialize SP | |
| 00c003 B608 00 | ldaa | Data_1 | ; Load from memory address RAM | |
| ; | ||||
| ORG | RAM | ; set program counter | ||
| ; to RAM for the data | ||||
| 000800 | Data_1: | DS.B | $20 | ; Set aside $20 bytes |
Software Development Process
When programming in any language, following a good development process is necessary in order to deliver a successful product. It is important to resist the urge to jump right into the code immediately, especially when programming in assembly which is extremely complex.
The first step should always be to clearly identify the problem and define a solution to solve that problem. Create and understand the solution in diagrams or pseudo-code before beginning to code in assembly. Translating these diagrams into code will be much easier than trying envision the solution entirely in your mind.
Debugging and tracing through your assembly program will also be a very good way at finding and correcting bugs.
Typical Bugs Include:
- Incorrect transfer to sub-routine
- Forgetting to initialize the stack pointer
- Not enough memory in the stack
- Sub-routines corrupting registers
- Forgetting to initialize index registers
- Modifying the condition code registers before branching
- Using the wrong branching instruction
- Using the wrong addressing mode
D-Bug12
The D-Bug12 is the debugging tool stored in the EEPROM of our microcontroller that will be used for debugging as well as for downloading programs onto the card and controlling the assembler.
D-Bug12 Commands
ASM – Assemble/Dissasemble
BF – Block Fill Memory
BR – Set Breakpoint
CALL – Call and execute subroutine
G – Go, run program
GT – Go till an address
HELP – Prints summary of available commands
LOAD – Set in state ready to accept program download from MiniIDE
MD – Display Contents of Memory
MM – Modify Memory
MOVE – Copy block of memory
NOBR – Remove breakpoints
RD – Display register contents
T – Trace through program
UPLOAD – Upload memory to PC
USEHDB – Use EVB/Target hardware breakpoints
VERIF – Compare memory to download file
—
[1] Fredrick M. Cady, Software and Hardware Engineering: Assembly and C Programming for the Freescale HCS12 Microcontroller
[2] Prof. Gilbert Arbez, University of Ottawa CSI3531 Course Notes, Module 3